There's one extremely simple trick, however, that can make your dialogue stand out from everything else in the mix, which makes it easier for your audience to focus on and comprehend said dialogue. It's an equalization trick called notching, and Curtis Judd has an excellent tutorial to show you how it's done.
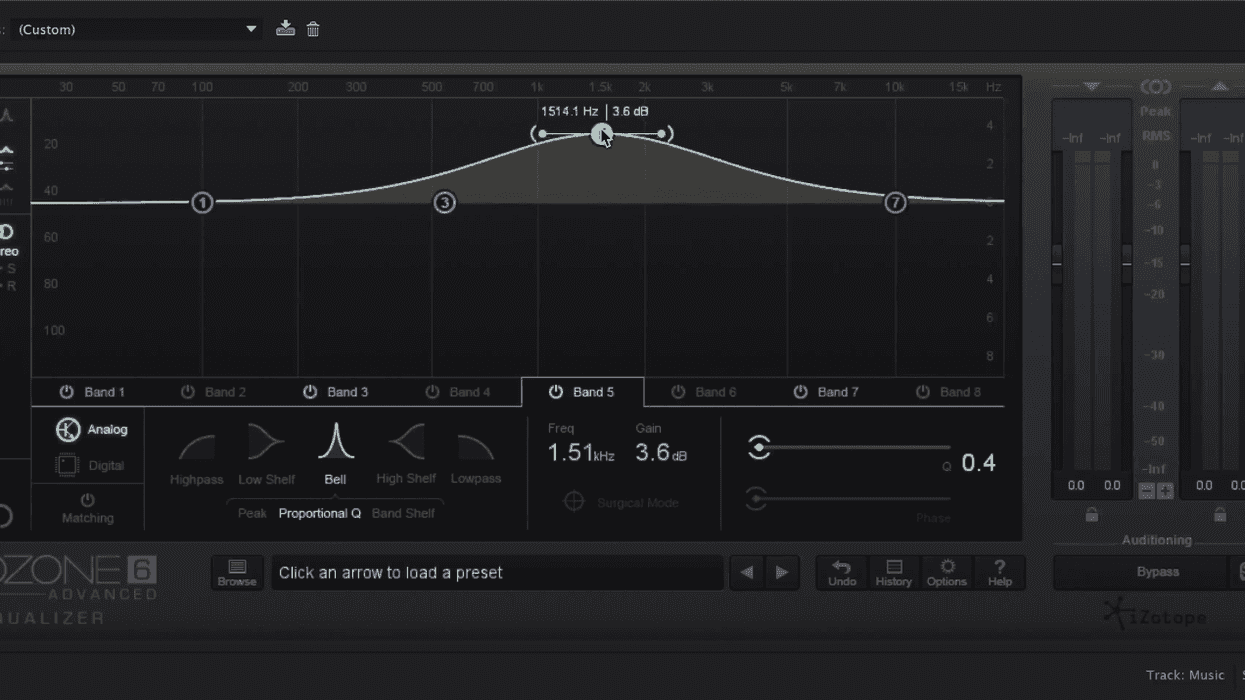
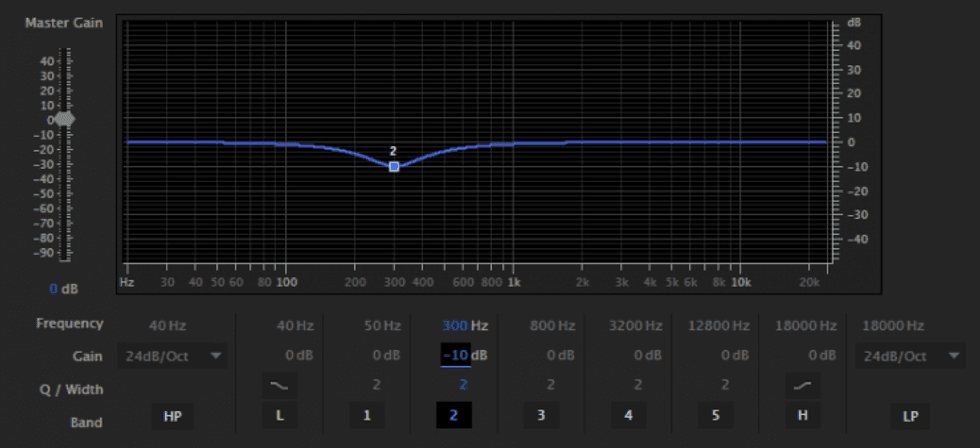
What is notching, you ask? Well, if you imagine a parametric EQ interface -- essentially a graph where the horizontal axis represents frequency and the vertical axis represents volume -- a notch is where you pull the volume a specific frequency down. It's a simple as that. Here's a good visual representation of that concept taken from the Parametric EQ effect in Adobe Audition. In this example, I've pulled down the frequency at 300Hz by about 10dB.
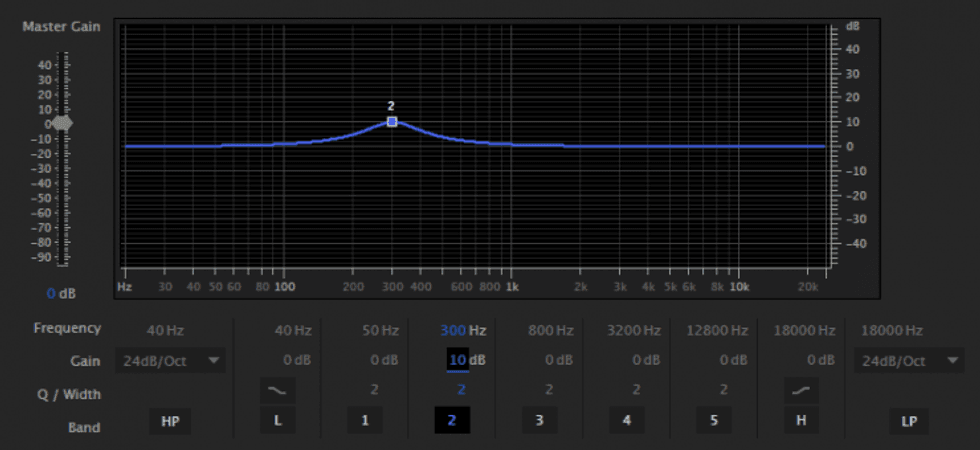
Because the human voice generally sits in a wide frequency range between roughly 50Hz-2kHz, pulling this particular frequency down (if we assume it's a deeper male voice) on any music or SFX tracks that are clashing with your dialogue will result in more clarity and punch in that dialogue. For an added boost to really separate the dialogue from other audio in the mix, you can slightly boost the same frequencies on your dialogue tracks. Here's what that looks like.
This is one of those techniques where just a little bit of "notching" goes a long way. Audio can start to sound unnatural when certain frequencies are pushed too high or low in the mix, so a good rule of thumb is to start small, notching out the problematic frequency by -5dB or so. If that's not enough to clear up your dialogue, you can then try deepening that notch even more, maybe to -10dB, and boosting the same frequency on the dialogue track.
Additionally, it can be tricky to figure out which particular frequency to notch because every human voice is different (which sometimes means that you need to apply this technique multiple times if you're mixing, say, a conversation between a male and female with drastically different voices). You can use tools like the spectral frequency display in Audition to figure out which frequencies are most prevalent in your dialogue track, and then apply a parametric EQ to notch those frequencies. Last but not least, notching can be subjective. Some people prefer to keep their notch between 1kHz and 2kHz, whereas others will opt for using lower frequencies.
Do you guys use EQ notching to make dialogue clearer and more easily audible? Which frequencies do you prefer to use? Let us know down in the comments!
Source: Curtis Judd










