
There’s only so many ways in which you can talk about AI in film and video before you have to settle on the obvious conclusion: if any of us want to have any sort of career in this industry going forward, we’re going have to get used to using AI.
And that inevitable future just became quite a bit more realized with Google’s new AI video generator finally being revealed. Dubbed ‘Lumiere’ (in a not-so-subtle nod to the fathers of moving pictures themselves, the Lumière brothers), this new AI video generator looks to be one of the most advanced text-to-video models yet.
Let’s take a look at Google’s generative AI play and explore how it works, what the results look like so far, and — sadly — how we could expect the industry to shift with this new player now officially on the scene.
Google Lumiere AI Video Generator
Now, we’ll get more into what it means that Google is the company behind this AI video generator in a second, but for now, let’s take a quick look at Lumiere itself (including the demo video linked below). Lumiere is a text-to-video model that can generate full scenes with just a simple text input.
Off the bat, it looks quite similar to other text-to-video models which we’ve seen (and covered) like Runway, Pika, and Midjourney, but Google promises that its version will be able to eventually surpass its competition.
For now though, the demo showcases mostly clips of animals being generated from prompts, as well as the AI video generator using real photos as source material. However, the most impressive elements of this new AI at launch will probably be its strong animation and stylization controls.
Video Stylization and Cinemagraphs
One fun-looking feature for sure in Lumiere is a “Video Stylization” setting that looks to allow users the ability to upload a source video, then prompt the generative AI model to provide various element changes to it. We’ve seen some different versions in the past, but for concept artists to graphic designers, this could be huge for creating content that’s on-brand and in the style of an overall project.
There’s also a new feature called “Cinemagraphs” that allows users to animate just one section of a video or image. (This is similar to the Motion Brush feature which we’ve seen introduced to Runway as well.) There’s also a “Video Inpainting” feature that allows users to mask certain parts to generate without changing the rest of the video (again, similar to Adobe’s Generative Fill feature as well).
Now, while the most revolutionary aspects of this new generative AI model might not be the overall results just yet, there is reason to be concerned that this AI video generator might be a more serious player than it at first appears. This is in part due to the AI model itself.
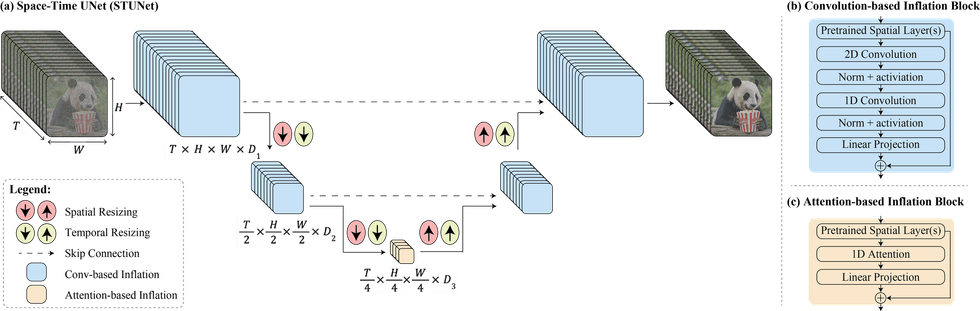
Google's Space-Time U-Net architecture
A New Space-Time Diffusion Model
Dubbed by Google as a “space-time diffusion model” that is powered by “Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model,” it sounds like this is an entirely new way for generative AI to work.
There’s not a lot of info out yet about exactly what’s going on behind the scenes as Google understandably will look to keep it as secretive as possible, but it does promise to be a much faster-learning and quicker-to-grow model out there — and the future leading force in this arena.
All that being said, it’s increasingly looking like new generative AI models are going to give creators (and producers) the tools they need to generate prompt-based video that will start being used for all types of commercial projects.
- How AI Video Repurposing Tools Turn Long Videos Into Viral Shorts ›
- How Is President Biden Influencing the Future of AI Video Content? ›
- Preview Your AI Models with Direct Comparison UI With Topaz Video AI 4.0 ›
- AI Video Editor Dreamix Brings Generated Video Closer to Reality ›
- 5 Reasons AI Will (Probably) Never Replace Human Video Editors ›
- AI Face Tracking Data for 3D Animation Takes Step Forward ›
- Here’s How Sora’s AI Video Could be Good for Filmmakers ›










