
We weren’t kidding when we said that generative AI video is moving fast. Just as we reported the news of Pika Labs launching Pika 1.0 and their insane new text-to-video AI model, we’re here sharing news of Stable Diffusion making their own big strides in the AI video space as well.
Regardless of how you feel about AI, it’s hard to deny that this new technology isn’t going to absolutely revolutionize the film and video world. The real question isn’t even how much now, but rather just how soon.
Stable Diffusion, which we’ve covered in the past, has been a staple in this budding AI economy mostly with their AI-generated art capabilities. However, with their new generatie video process created by Stability.Ai and which they called Stability Video Diffusion, image-to-video appears to be here as well.
Here’s everything you need to know about this new Stable Video Diffusion.
Introducing Stable Video Diffusion
Now available just as a research preview, this new state-of-the-art generative AI video model represents a significant step in Stable DIffusion’s journey towards creating AI models for all creator types. Simply dubbed Stable Video Diffusion, it's the company’s first foundation model for generative video based on their popular image model Stable Diffusion.
And, for those interested in the technical aspects of this research preview, Stable Diffusion has made the code for this Stable Video Diffusion available on their GitHub repository and the weights required to run the model are available on their Hugging Face page. And, as an added bonus if you really want to geek out, you can read all of the technical capabilities of the model in their published research paper.
But, basically in layman’s terms, this new Stability Video Diffusion process will be allow creators to combine uploading a single image with a text-based description and have Stable Diffusion’s AI algorithm generate them a video clip that will most likely be around four seconds in length and with a frame rate between 3 and 30 fps.
How Does it Work?
And, while you can of course read through all the technical aspects yourself, the basics of this new image-to-video AI technology do look pretty promising and should rival that of the also just released Pika 1.0.
With their Stable Video Diffusion process, these AI-generated videos should most likely end up being videos of 14 or 25 frames at just around a 576×1024 pixel resolution. So, these aren’t going to be 4K videos which you can share with clients just yet. Instead they’ll likely look more akin to an animated GIF for now.
However, this technology is not a one-off endeavor as Stable Diffusion is most certainly going to improve on this tech quite quickly and larger and more complex videos are certainly in the cards. Which is good or bad depending on your view here, but it’s also worth noting that this initial launch will only focus on hand-drawn animation styles, and it isn’t ready to handle realistic live video renders just yet.
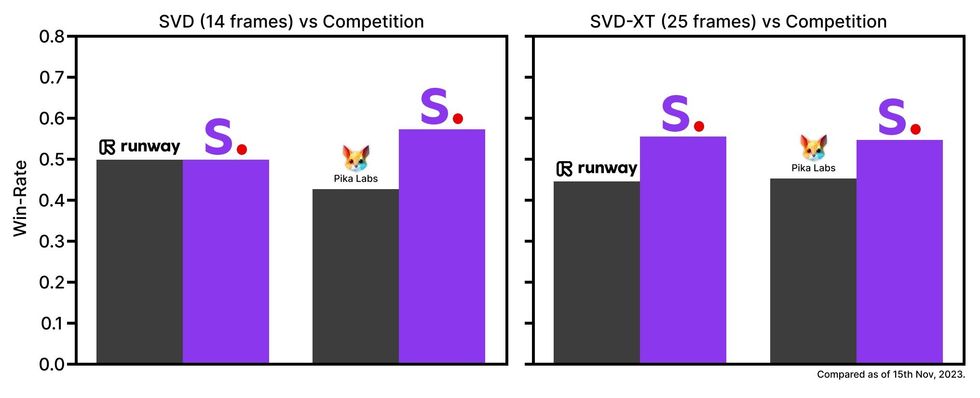
A look at how stability.ai stacks up to its AI competition
Stable Diffusion
What Comes Next?
For those of us that aren’t deep into the world of AI and machine learning (just yet at least), the better question than how it works is simply what comes next. For Stable Diffusion it sounds like that after this research phase is complete this new Stable Video Diffusion will directly be released as an app similar to their current Stable Diffusion AI image generator.
From there we’ll most likely see some sort of Pro plan offering similar to Stable Diffusion and other similar AI apps and tools. However, what’s perhaps more pressing is simply trying to gauge how quickly this AI technology, along with the other AI generative video tools, are able to replicate photorealistic video and creep further into the film and video world.
Only time will be able to tell on that front. But for now, if you are interested, you can sign-up for the waitlist to get started with Stable Video Diffusion and its text-to-video interface now.- How Does SDXL 1.0 Evolve Text-to-Image Generation? ›
- Is the Future of AI-Powered Text Generation Here? ›
- Why Filmmakers and Creatives Should Not Worry About AI Tools ›
- Filmmaker Paul Trillo Uses AI Like a Paintbrush To Create His New Short Film ›
- How Midjourney v5.2’s Zoom Out Feature Could Shape AI Video ›
- AI Just Got More Creative, and Filmmakers Shouldn’t Be Afraid ›
- How To Use Runway AI for Video Editing ›
- These AI Tools From Runway Will Help You Create Original Videos ›
- Meta Introducing Its Own Generative AI with Emu Video and Emu Edit ›
- Warner Bros. Promises to Protect the Artists Against AI ›
- Runway vs Pika Labs: Which is the Best Image-to-Video AI? ›
- AI Dubbing Can Instantly Change Actors’ Language and Accents ›










